Redis优化实例分析
内存维度
控制key的长度
key的一般都是采用字符串,而字符串的底层数据结构为SDS,SDS 结构中会包含字符串长度、分配空间大小等元数据信息,当key字符串的长度增加时,SDS中的元数据也会占用更多内存空间,为了减少key的占用空间,我们可用根据业务名来使用相应的英文缩写来表示。例如user用u表示,message 用m来表示。
避免存储bigkey
我们既要注意key的长度,同时也需要关注value的大小,Redis是使用单线程读写数据,bigkey 的读写操作会阻塞线程,降低Redis的处理效率。
如何查询bigkey
我们可以通过--bigkey的命令来查看Redis中所占用的bigkey的信息,具体的命令如下:
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
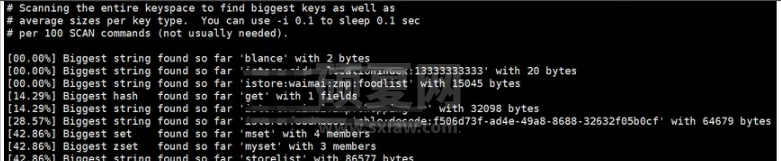
从上述图所示,我们可以查看到Redis中的key占用了32098个bytes,需要进行相关优化的。
建议:
如果key为string类型,建议value的存放值的大小为10KB左右。
如果key为List/Hash/Set/ZSet类型,建议存放元素的的数量控制在1万以下。
选择合适的数据类型
Redis针对所存储的数据类型进行了优化,同时也对内存进行了相应的优化。关乎数据结果的相关知识,可以参考之前的文章。
例如:String和set在存储int数据时,会采用整数编码存储。Hash、ZSet在元素数量比较少时,会采用压缩列表(ziplist)存储,在存储比较多的数据时,才会转换为哈希表和跳表。
采用高效的序列化和压缩方法
Redis中的字符串都是使用二进制安全的字节数组来保存的,所以我们可以把业务的序列化成二进制写入Redis,但是采用不同的序列化,所占用的空间大少不一样。Protostuff的序列化比Java内置的序列化更有效率,且占用的空间更少。为了减少空间占用,我们可以对JSON和XML数据格式进行压缩存储,可选的压缩算法包括Gzip和Snappy。
设置Redis最大内存和淘汰策略
我们根据业务的数据量提前预估内存大小,从而避免Redis的内存持续膨胀,导致占用过多资源。
关于如何设置淘汰策略,需要集合实际的业务特性来选择:
volatile-lru / allkeys-lru:优先保留最近访问过的数据
volatile-lfu / allkeys-lfu:优先保留访问次数最频繁的数据
volatile-ttl :优先淘汰即将过期的数据
volatile-random / allkeys-random:随机淘汰数据
控制Redis实例的大小
Redis单实例的内存大小建议设置在2~6GB之间。由于RDB快照和主从集群数据同步都能快速完成,不会阻塞正常请求的处理。
定时清除内存碎片
频繁的新增修改会导致内存碎片的增多,因此需要及时清理内存碎片。
Redis提供了Info memory命令可以查看内存使用信息,具体如下:
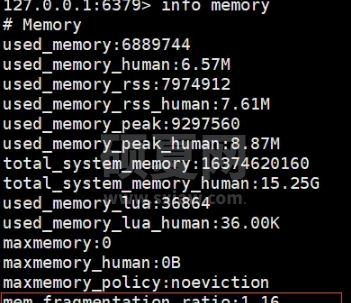
说明:
used_memory_rss是操作系统实际分配给 Redis的物理内存空间。
used_memory 是 Redis 为了保存数据实际申请使用的空间。
mem_fragmentation_ratio=used_memory_rss/ used_memory
mem_fragmentation_ratio 大于1但小于1.5。这种情况是合理的。
如果mem_fragmentation_ratio大于1.5,意味着内存碎片率已经达到50%以上。在这种情况下,通常需要采取一些措施来减少内存碎片率。具体的内存清理措施,将在后续的文章中进行讲解。
性能维度
禁止使用KEYS、FLUSHALL、FLUSHDB命令
KEYS 按照key内容进行匹配,返回符合匹配条件的键值对,该命令需要对Redis的全局哈希表进行全表扫描,严重阻塞 Redis主线程。
FLUSHDB,删除当前数据库中的数据,如果数据量很大,会阻塞Redis主线程。
优化建议
我们需要在线上要禁用这些命令。具体的做法是,管理员采用rename-command命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令。
慎用全量操作的命令
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
慎用复杂度过高命令
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
设置合适的过期时间
Redis通常用于保存热数据。热数据一般都有使用的时效性。因此,在数据存储的过程中,应根据业务对数据的使用时间合理地设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
采用批量命令代替个命令
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
String或者Hash类型可以使用 MGET/MSET替代 GET/SET,HMGET/HMSET替代HGET/HSET
其它数据类型使用Pipeline命令,一次性打包发送多个命令到服务端执行。
Pipeline具体使用:
redisTemplate.executePipelined(new RedisCallback<String>() { @Override public String doInRedis(RedisConnection connection) throws DataAccessException { for (int i = 0; i < 5; i++) { connection.set(("test:" + i).getBytes(), "test".getBytes()); } return null; } });
高可用维度
按照业务部署不同的实例
不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
避免单点问题
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
合理的设置相关参数
针对主从环境,我们需要合理设置相关参数,具体内容如下:
合理的设置repl-backlog参数:如果repl-backlog设置过小,当写流量比较大的场景下,主从复制中断可能会引发全量复制数据的风险。
合理设置slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer会导致从库缓冲区溢出,从而导致复制中断。
以上就是Redis优化实例分析的详细内容,更多请关注www.sxiaw.com其它相关文章!