MySQL不适合构建索引及索引失效的情况有哪些
结论
具体案例下文有详尽描述
不适合建立索引的场景:
数据量比较小的表不建议建立索引
有大量重复数据的字段上不建议建立索引(类似:性别字段)
需要进行频繁更新的表不建议建立索引
where、group by、order by后面的没有使用到的字段不建立索引
不要定义冗余索引
索引失效的场景:
过滤条件使用不等于(!=、<>)
过滤条件使用is not null
在索引字段上使用函数或进行计算
在使用联合索引的时候,需要满足“最佳左前缀法则”,否则失效
当使用了类型转换也会导致索引失效
在使用范围查询的时候,联合索引的部分字段失效(where age >18)
在like字段中,如果是以%开头,索引失效(where name like ‘%abc’)
在使用or进行查询的时候,or前后出现非索引字段,索引失效
表和库的字符集不一致,回导致索引失效
知识点:
每张表的索引不建议超过6个(占用空间、降低表更新速度)
最终到底是否使用索引还是优化器进行决定的
优化器会根据数据量、数据库版本、数据选择读进行查询代价的比较,从而决定是否使用索引
建立索引的时候将需要范围匹配的字段建立在索引的尾部,避免失效
在建立表的时候将字段设置为not null同时设置默认值,当需要查找没有值的记录的时候就可以使用where xxx = 默认值,放置使用is not null导致索引失效
在页面搜索时,请使用左侧或全文模糊匹配(like '%abc')
对于过滤性较好的字段建立在联合索引的前面,这样就可以优先过滤比较多的数据
不建议建立索引的场景
场景一:数据少的表
当数据比较少的时候,索引的优势就不明显了,因为数据库的存储引擎也是非常快的,相较于需要查询索引在进行回表操作,可能直接查询的性能会更高一些,所以数据相对较少的表不建议建立索引
场景二:有大量重复数据的字段
类似于性别字段,只有“男”和“女”两个不同的值,所以索引一半的数据是“男”一半的数据是“女”,那么建立索引并不能进行快速的查询等,所以不建议在有大量重复数据的列上建立索引
场景三:频繁更新的表(update/delete/insert)
因为表中更新数据的时候,索引也是需要进行对应的维护的,如果一个表近期需要频繁的进行增删改操作,那么就需要耗费大量的时间去维护索引,不建议建立索引,可以在需要进行频繁的更新操作的时候将索引删除,更新完毕之后重建索引
场景四:没有使用的字段(where/group by/order by)
不是where/group by/order by后面的字段没有必要建立索引,因为不会使用到该索引
场景五:不要定义冗余索引
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现
这里因为username作为第一个联合索引的第一个字段,所以索引就是按照username进行排序,在username相同的情况下按照password、address排序,所以也就是实现了单独拿username列作为索引的功能,即第二个索引就是多余的
索引失效的场景
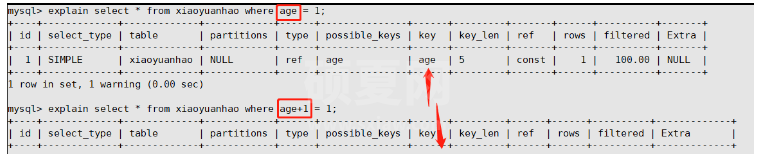
场景一:在建立索引的字段上进行运算(函数等),导致索引失效
这里首先是给age创建了索引,在第一次查询过程中使用了age索引,但是第二次key值为null(索引失效),导致索引失效的原因在于第二次查询的时候where后面对age进行了计算,计算机并不知道执行的是什么计算所以会将age+1计算后与1比较,索引失效
类似于在字段上使用函数concat()等都会导致索引失效
场景二:使用不等于(where age != 18)
当使用等值运算,那么是可以在索引中进行查找的,但是如果是不等于,那么则需要遍历所有数据,所以所失效
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效
场景三:使用is not null索引失效
与不等于一样,如果使用的是is not null,那么就需要进行全部数据的遍历操作,索引失效,但是如果使用的是is null那么依旧是可以使用索引的
--这里是在age字段上建立了普通索引,第二个查询时候索引失效 explain select * from xiaoyuanhao where age is null; --可以正常使用索引 explain select * from xiaoyuanhao where age is not null; --索引失效
场景四:在使用联合索引的时候没有遵循最佳左前缀法则
CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效

从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效


场景五:类型转换导致索引失效
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name

发生了类型转换,无法使用索引kye = null,索引失效

使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效

key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
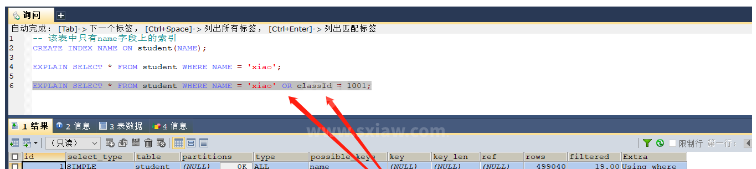
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
以上就是MySQL不适合构建索引及索引失效的情况有哪些的详细内容,更多请关注www.sxiaw.com其它相关文章!