MySQL数据库索引原理及优化策略是什么
1 索引
索引概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引作用
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系,索引所起的作用类似书籍目录,可用于快速定位、检索数据。索引可以极大地提高数据库的性能。
索引的使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询。
该数据库表的插入操作,及对这些列的修改操作频率较低。
索引会占用额外的磁盘空间。
2 索引分类
从索引存储结构划分:BTree索引、Hash索引、FULLTEXT全文索引、RTree索引
从应用层次划分:普通索引,唯一索引,主键索引,复合索引
从索引键值类型划分,主键索引,辅助索引(二级索引)
从数据存储和索引键值逻辑关系划分:聚集索引(聚簇索引)非聚集泰引(非聚簇索)
从索引列数量划分:单列索引,复合索引
B树索引和B+树索引区别

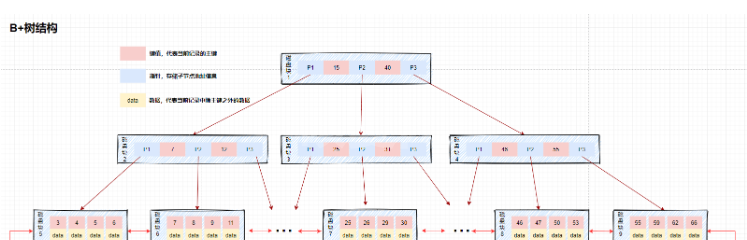
区别:
数据的保存位置不同:B+树保存在叶子节点,B树保存在所有的节点中
体现出B+树优势:节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。 查询性能稳定:每次查询都是从根节点遍历到叶子节点,查询路径长度相同,即每次查询效率相当,时间复杂度固定是O(log(n))
叶子节点的指向:B+树相邻的叶子节点通过指针相连,B树没有
体现出B+树优势:所有叶子节点形成有序链表,便于范围查找
3 索引操作
创建主键索引
-- 在创建表的时候,直接在字段名后指定 primary key create table user1(id int primary key, name varchar(30)); -- 在创建表的最后,指定某列或某几列为主键索引 create table user2(id int, name varchar(30), primary key(id)); -- 创建表以后再添加主键 create table user3(id int, name varchar(30)); alter table user3 add primary key(id);
主键索引的特点:
一个表中,最多有一个主键索引,当然可以使符合主键
主键索引的效率高(主键不可重复)
创建主键索引的列,它的值不能为null,且不能重复
主键索引的列基本上是int
唯一索引的创建
-- 在表定义时,在某列后直接指定unique唯一属性。 create table user4(id int primary key, name varchar(30) unique); -- 创建表时,在表的后面指定某列或某几列为unique create table user5(id int primary key, name varchar(30), unique(name)); -- 创建表以后再添加unique create table user6(id int primary key, name varchar(30)); alter table user6 add unique(name);
唯一索引的特点:
一个表中,可以有多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,等价于主键索引
普通索引的创建
--在表的定义最后,指定某列为索引 create table user8(id int primary key, name varchar(20), email varchar(30), index(name) ); --创建完表以后指定某列为普通索引 create table user9(id int primary key, name varchar(20), email varchar(30)); alter table user9 add index(name); -- 创建一个索引名为 idx_name 的索引 create table user10(id int primary key, name varchar(20), email varchar(30)); create index idx_name on user10(name);
普通索引的特点:
一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
查询索引
show keys from 表名
mysql> show keys from goods\G
*********** 1. row ***********
Table: goods <= 表名
Non_unique: 0 <= 0表示唯一索引
Key_name: PRIMARY <= 主键索引
Seq_in_index: 1
Column_name: goods_id <= 索引在哪列
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE <= 以二叉树形式的索引
Comment:
1 row in set (0.00 sec)
show index from 表名;
desc 表名
删除索引
删除主键索引: alter table 表名 drop primary key;
其他索引的删除: alter table 表名 drop index 索引名; 索引名就是show keys from 表名中的Key_name 字段
mysql> alter table user10 drop index idx_name;
drop index 索引名 on 表名
mysql> drop index name on user8
索引创建原则
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合作创建索引
不会出现在where子句中的字段不该创建索引
以上就是MySQL数据库索引原理及优化策略是什么的详细内容,更多请关注www.sxiaw.com其它相关文章!