Apache Camel 与 Quarkus 实用指南:构建 ETL 应用程序
我很高兴向大家介绍一系列有关 apache camel 的文章。在第一篇文章中,我将介绍一个实际用例来展示其功能,而不是深入研究 apache camel 的复杂性。具体来说,您将学习如何使用 apache camel 在两个数据库之间创建简单的提取、转换和加载 (etl) 应用程序。
apache camel 简介 - 简要概述
在深入实际用例之前,我们先简单介绍一下 apache camel。 apache camel 是一个开源集成框架,它利用企业集成模式(eip)来促进各种系统的集成。
当今世界,众多不同类型的系统并存。有些可能是遗留系统,而另一些则是新系统。这些系统通常需要相互交互和集成,由于不同的实现和消息格式,这可能具有挑战性。一种解决方案是编写自定义代码来弥合这些差异,但这可能会导致紧密耦合和维护困难。
相反,apache camel 提供了一个额外的层来调解系统之间的差异,从而实现松散耦合并更易于维护。 camel 使用 api(或声明性 java 域特定语言)来配置基于 eip 的路由和中介规则。
企业集成模式 (eip)
要了解 apache camel,掌握“企业集成模式”(eip) 很重要。 《企业集成模式》一书描述了一组用于设计大型基于组件的系统的模式,其中组件可以在同一进程或不同机器上运行。关键思想是系统应该是面向消息的,组件通过消息进行通信。这些模式提供了用于实现这些通信的工具包(图 1)。
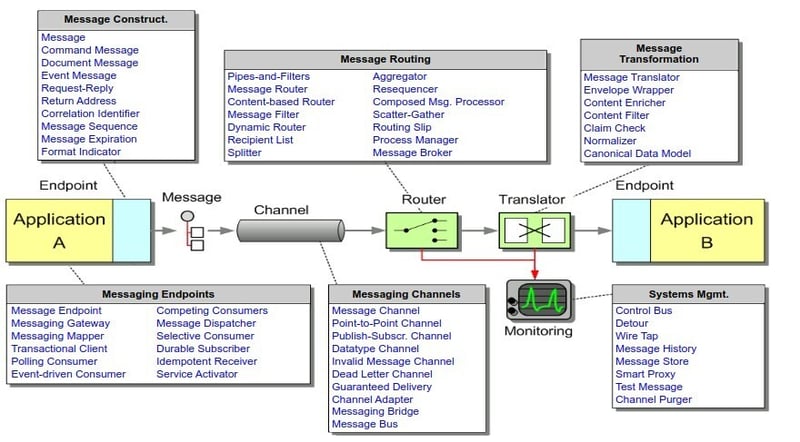
图 1 – 集成解决方案的基本元素 (enterpriseintegrationpatterns.com)
apache camel 中的关键术语
端点:端点是发送和接收消息的通道。它充当组件与外界之间的接口。
消息:消息是用于系统之间通信的数据结构,由消息头和消息体组成。标头包含元数据,正文包含实际数据。
通道:通道连接两个端点,方便消息的发送和接收。
路由器:路由器将消息从一个端点定向到另一个端点,确定消息路径。
翻译器:翻译器将消息从一种格式转换为另一种格式。
关于 apache camel 的介绍我考虑就到此为止。现在让我们向您展示如何使用 apache camel 在两个数据库之间创建简单的 etl 应用程序。
问题陈述
假设我们有一个高负载的系统,其中一个关键组件是数据库。在某些时候,我们需要在通常的操作案例之外处理这些数据 - 训练 ml 模型、生成导出、图表,或者我们只需要数据的某些部分。当然,这会给我们的操作数据库带来更大的负担,为此,最好有一种机制,通过它我们可以提取必要的数据,将其转换为我们需要的形式,并将其存储在另一个数据库中 - 其他比操作性的。通过这一策略,我们解决了运营基地潜在超载的问题。而且,通过这样的机制,我们可以在系统负载不太大的时候(例如夜间)执行此操作。
解决方案概述
解决方案如下图所示(图2)。我们将使用 apache camel 在两个数据库之间创建一个简单的 etl 应用程序。该应用程序将从源数据库中提取数据,对其进行转换,然后将其加载到目标数据库中。我们可以引入不同的策略来实现这个解决方案,重点关注如何从源数据库中提取数据。我假设选择数据的标准将基于记录的修改日期。此策略也提供了提取已修改数据的机会。
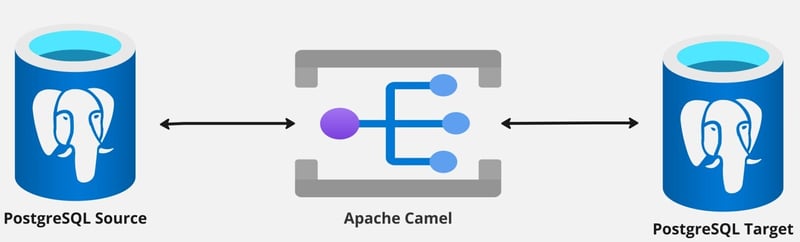
图 2 – 使用 apache camel 在两个数据库之间同步数据
源数据库和目标数据库将具有以下表结构:
create table if not exists user
(
id serial primary key,
username varchar(50) not null,
password varchar(50) not null,
email varchar(255) not null,
created_at timestamp default now()::timestamp without time zone,
last_modified timestamp default now()::timestamp without time zone
);
在目标数据库中,我们将在插入之前将用户名转换为大写。
我们将为各种 camel 组件使用 camel quarkus 扩展。具体来说,我们将使用 camel sql 组件与数据库进行交互。 sql组件支持执行sql查询、插入、更新和删除。
首先,创建一个扩展 routebuilder 的类并重写配置方法:
@applicationscoped
public class userroute extends routebuilder {
@override
public void configure() throws exception {
// your code here
}
}
这里不强制使用 @applicationscoped 注解,但我更愿意表明该类是一个 cdi bean,并且应该由 cdi 容器管理。
正如我上面提到的,我们将使用 camel sql 组件与数据库交互。我们需要配置camel sql组件来连接源数据库和目标数据库。我们将使用 quarkus agroal 扩展来配置数据源。 agroal 扩展为数据源提供了一个连接池。我们将在 application.properties 文件中配置数据源。
# # source database configuration quarkus.datasource.source_db.db-kind=postgresql quarkus.datasource.source_db.jdbc.url=jdbc:postgresql://localhost:5001/demo quarkus.datasource.source_db.username=test quarkus.datasource.source_db.password=password1 # # # target database configuration quarkus.datasource.target_db.db-kind=postgresql quarkus.datasource.target_db.jdbc.url=jdbc:postgresql://localhost:6001/demo quarkus.datasource.target_db.username=test quarkus.datasource.target_db.password=password1 #
现在我们可以配置camel sql组件来连接源数据库和目标数据库。我们将使用 sql 组件为源数据库和目标数据库创建 sql 端点。
sql 组件使用以下端点 uri 表示法:
sql:select * from table where id=# order by name[?options]
但是我们需要机制来自动运行该操作。我们将使用计时器组件每秒触发一次 etl 过程。计时器组件用于在计时器触发时生成消息交换。计时器组件使用以下端点 uri 表示法:
timer:name[?options]
在我们的路线中,我们使用如下配置:
from("timer://usersync?delay={{etl.timer.delay}}&period={{etl.timer.period}}")
{{etl.timer.delay}} 和 {{etl.timer.period}} 是我们将在 application.properties 文件中定义的配置值。
etl.timer.period=10000 etl.timer.delay=1000
为了在将数据插入目标数据库之前转换数据,我们需要提供翻译器:
.process(exchange -> {
final map<string object> rows = exchange.getin().getbody(map.class);
final string username = (string) rows.get("username");
final string usernametouppercase = username.touppercase();
log.info("user name: {} converted to upper case: {}", username, usernametouppercase);
rows.put("username", usernametouppercase);
})
</string>
处理器接口用于实现消息交换的使用者或实现消息转换器和其他用例。
瞧,我们使用 apache camel 在两个数据库之间建立了一个简单的 etl 应用程序。
运行应用程序时,您应该在日志中看到以下输出:
2024-06-09 13:15:49,257 INFO [route1] (Camel (camel-1) thread #1 - timer://userSync) Extracting Max last_modified value from source database 2024-06-09 13:15:49,258 INFO [route1] (Camel (camel-1) thread #1 - timer://userSync) No record found in target database 2024-06-09 13:15:49,258 INFO [route2] (Camel (camel-1) thread #1 - timer://userSync) The last_modified from source DB: 2024-06-09 13:15:49,274 INFO [route2] (Camel (camel-1) thread #1 - timer://userSync) Extracting records from source database 2024-06-09 13:15:49,277 INFO [org.iqn.cam.rou.UserRoute] (Camel (camel-1) thread #1 - timer://userSync) User name: john_doe converted to upper case: JOHN_DOE 2024-06-09 13:15:49,282 INFO [org.iqn.cam.rou.UserRoute] (Camel (camel-1) thread #1 - timer://userSync) User name: jane_smith converted to upper case: JANE_SMITH 2024-06-09 13:15:49,283 INFO [org.iqn.cam.rou.UserRoute] (Camel (camel-1) thread #1 - timer://userSync) User name: alice_miller converted to upper case: ALICE_MILLER
您可以在 github 存储库中找到该应用程序的完整源代码。
结论
通过此设置,我们使用 apache camel 创建了一个简单的 etl 应用程序,该应用程序从源数据库中提取数据,对其进行转换,然后将其加载到目标数据库中。这种方法有助于减少操作数据库的负载,并允许我们在非高峰时间执行数据提取。
以上就是Apache Camel 与 Quarkus 实用指南:构建 ETL 应用程序的详细内容,更多请关注www.sxiaw.com其它相关文章!