nginx惊群问题如何解决
1. 解决方式
每个worker进程被创建的时候,都会调用ngx_worker_process_init()方法初始化当前worker进程,这个过程中有一个非常重要的步骤,即每个worker进程都会调用epoll_create()方法为自己创建一个独有的epoll句柄。对于每一个需要监听的端口,都有一个文件描述符与之对应,而worker进程只有将该文件描述符通过epoll_ctl()方法添加到当前进程的epoll句柄中,并且监听accept事件,此时才会被客户端的连接建立事件触发,从而处理该事件。从这里也可以看出,worker进程如果没有将所需要监听的端口对应的文件描述符添加到该进程的epoll句柄中,那么其是无法被触发对应的事件的。基于这个原理,nginx就使用了一个共享锁来控制当前进程是否有权限将需要监听的端口添加到当前进程的epoll句柄中,也就是说,只有获取锁的进程才会监听目标端口。通过这种方式,就保证了每次事件发生时,只有一个worker进程会被触发。如下图所示为worker进程工作循环的一个示意图:
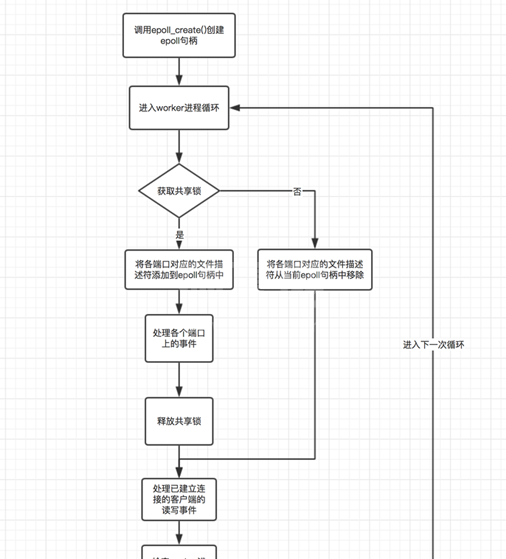
这里关于图中的流程,需要说明的一点是,每个worker进程在进入循环之后就会尝试获取共享锁,如果没有获取到,就会将所监听的端口的文件描述符从当前进程的epoll句柄中移除(即使并不存在也会移除),这么做的主要目的是防止丢失客户端连接事件,即使这可能造成少量的惊群问题,但是并不严重。试想一下,如果按照理论,在当前进程释放锁的时候就将监听的端口的文件描述符从epoll句柄中移除,那么在下一个worker进程获取锁之前,这段时间各个端口对应的文件描述符是没有任何epoll句柄进行监听的,此时就会造成事件的丢失。如果反过来,按照图中的在获取锁失败的时候才移除监听的文件描述符,由于获取锁失败,则说明当前一定有一个进程已经监听了这些文件描述符,因而此时移除是安全的。但是这样会造成的一个问题是,按照上图,当前进程在一个循环执行完毕的时候,会释放锁,然后处理其他的事件,注意这个过程中其是没有释放所监听的文件描述符的。此时,如果另一个进程获取到了锁,并且监听了文件描述符,那么这个时候就有两个进程监听了文件描述符,因而此时如果客户端发生连接建立事件,那么就会触发两个worker进程。这个问题是可以容忍的,主要原因有两点:
这种惊群现象只会触发较少数量的工作进程,相比每次都惊醒所有工作进程要好得多
会发生这种惊群问题的主要原因是,当前进程释放了锁,但是没有释放所监听的文件描述符,但是worker进程在释放锁之后主要是处理客户端连接的读写事件和检查标志位,这个过程是非常短的,在处理完之后,其就会尝试获取锁,这个时候就会释放所监听的文件描述符了,而相较而言,获取锁的worker进程在等待处理客户端的连接建立事件的事件就更长了,因而会发生惊群问题的概率还是比较小的。
2. 源码讲解
worker进程初始事件的方法主要是在ngx_process_events_and_timers()方法中进行的,下面我们就来看看该方法是如何处理整个流程的,如下是该方法的源码:
void ngx_process_events_and_timers(ngx_cycle_t *cycle) {
ngx_uint_t flags;
ngx_msec_t timer, delta;
if (ngx_trylock_accept_mutex(cycle) == ngx_error) {
return;
}
// 这里开始处理事件,对于kqueue模型,其指向的是ngx_kqueue_process_events()方法,
// 而对于epoll模型,其指向的是ngx_epoll_process_events()方法
// 这个方法的主要作用是,在对应的事件模型中获取事件列表,然后将事件添加到ngx_posted_accept_events
// 队列或者ngx_posted_events队列中
(void) ngx_process_events(cycle, timer, flags);
// 这里开始处理accept事件,将其交由ngx_event_accept.c的ngx_event_accept()方法处理;
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
// 开始释放锁
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
// 如果不需要在事件队列中进行处理,则直接处理该事件
// 对于事件的处理,如果是accept事件,则将其交由ngx_event_accept.c的ngx_event_accept()方法处理;
// 如果是读事件,则将其交由ngx_http_request.c的ngx_http_wait_request_handler()方法处理;
// 对于处理完成的事件,最后会交由ngx_http_request.c的ngx_http_keepalive_handler()方法处理。
// 这里开始处理除accept事件外的其他事件
ngx_event_process_posted(cycle, &ngx_posted_events);
}上面的代码中,我们省略了大部分的检查工作,只留下了骨架代码。首先,worker进程会调用ngx_trylock_accept_mutex()方法获取锁,这其中如果获取到了锁就会监听各个端口对应的文件描述符。然后会调用ngx_process_events()方法处理epoll句柄中监听到的事件。接着会释放共享锁,最后就是处理已建立连接的客户端的读写事件。下面我们来看一下ngx_trylock_accept_mutex()方法是如何获取共享锁的:
ngx_int_t ngx_trylock_accept_mutex(ngx_cycle_t *cycle) {
// 尝试使用cas算法获取共享锁
if (ngx_shmtx_trylock(&ngx_accept_mutex)) {
// ngx_accept_mutex_held为1表示当前进程已经获取到了锁
if (ngx_accept_mutex_held && ngx_accept_events == 0) {
return ngx_ok;
}
// 这里主要是将当前连接的文件描述符注册到对应事件的队列中,比如kqueue模型的change_list数组
// nginx在启用各个worker进程的时候,默认情况下,worker进程是会继承master进程所监听的socket句柄的,
// 这就导致一个问题,就是当某个端口有客户端事件时,就会把监听该端口的进程都给唤醒,
// 但是只有一个worker进程能够成功处理该事件,而其他的进程被唤醒之后发现事件已经过期,
// 因而会继续进入等待状态,这种现象称为"惊群"现象。
// nginx解决惊群现象的方式一方面是通过这里的共享锁的方式,即只有获取到锁的worker进程才能处理
// 客户端事件,但实际上,worker进程是通过在获取锁的过程中,为当前worker进程重新添加各个端口的监听事件,
// 而其他worker进程则不会监听。也就是说同一时间只有一个worker进程会监听各个端口,
// 这样就避免了"惊群"问题。
// 这里的ngx_enable_accept_events()方法就是为当前进程重新添加各个端口的监听事件的。
if (ngx_enable_accept_events(cycle) == ngx_error) {
ngx_shmtx_unlock(&ngx_accept_mutex);
return ngx_error;
}
// 标志当前已经成功获取到了锁
ngx_accept_events = 0;
ngx_accept_mutex_held = 1;
return ngx_ok;
}
// 前面获取锁失败了,因而这里需要重置ngx_accept_mutex_held的状态,并且将当前连接的事件给清除掉
if (ngx_accept_mutex_held) {
// 如果当前进程的ngx_accept_mutex_held为1,则将其重置为0,并且将当前进程在各个端口上的监听
// 事件给删除掉
if (ngx_disable_accept_events(cycle, 0) == ngx_error) {
return ngx_error;
}
ngx_accept_mutex_held = 0;
}
return ngx_ok;
}上面的代码中,本质上主要做了三件事:
通过ngx_shmtx_trylock()方法尝试使用cas方法获取共享锁;
获取锁之后则调用ngx_enable_accept_events()方法监听目标端口对应的文件描述符;
如果没有获取到锁,则调用ngx_disable_accept_events()方法释放所监听的文件描述符。
以上就是nginx惊群问题如何解决的详细内容,更多请关注www.sxiaw.com其它相关文章!